What I Learned From Processing All of Statistics Canada's Tables

Over the past few weeks I have processed all of Statistics Canada’s data tables (also known as cubes and referred as product_id in the tables embedded in this post) that are available through Statistics Canada’s Web Data Service (WDS). I have always been interested in making statistical data products easily accessible to users, and after analyzing the current way of disseminating data tables, I was able to make several improvements. In this blog post I will talk about (1) the problem, (2) what I was able to achieve, (3) issues encountered through processing the data, and (4) next steps.
1. Problem
As of July 6, 2025, there are 7918 data tables. There are two formats that can be downloaded, CSV, and XML, which are both disseminated as ZIP files. I chose to download the English CSV files. I downloaded 7918 ZIP files that amounted to 178.33 GB compressed, and 3314.57 GB uncompressed.
After working with the data for a bit I noticed the following problems:
- You first need to download a ZIP file, extract it, then process the dataset to your needs. That’s a lot of unnecessary steps. What if the data was just in a file format that was optimized for efficient data storage and retrieval. My goal is to allow users to easily link the Dissemination Geography Unique Identifier (DGUID) code to their geographic boundaries, so users can visualize all data tables in software such as QGIS and ArcGIS Pro.
- There is no site that keeps track of all changes to Statistics Canada’s data tables. That means that data can just dissapear without any accountability.
2. Result
I was able to process 7911/7918 data tables (99.91%) and created Parquet files that amounted to 25.73 GB (14.43% of the ZIP file size). Here is an interactive table with each data table, and the various file statistics:
2.1 Notable Changes Made to the Data Tables
Here are some notable changes made to the data tables:
- The Parquet files have optimized data types, so for example if the
VALUEcolumn is an integer, and has a maximum value of 2147483646, then the column is defined as a 32-bit integer; this is important as optimized data types means less memory usage when processing the file. - Two new columns were added to each data table:
REF_START_DATEandREF_END_DATE, that were based from theREF_DATEcolumn. This was added to enable date range queries via software such as DuckDB. The logic for theREF_START_DATEandREF_END_DATEcolumns is as follows:- When the
REF_DATEcolumn contained just the year (ex.2024), theREF_START_DATEwas set to2024-01-01and theREF_END_DATEwas set to2024-12-31. - When the
REF_DATEcolumn contained the year and month (ex.2024-01), theREF_START_DATEwas set to2024-01-01and theREF_END_DATEwas set to2024-01-31. - When the
REF_DATEcolumn contained the year, month, and day (ex.2024-01-01), theREF_START_DATEwas set to2024-01-01and theREF_END_DATEwas set to2024-01-01. - There were cases that I was unable to parse, such as a
REF_DATEset to2023/2024in table17100022. According to the metadata, the period is from July 1 to June 30, so I cannot just set January 1, 2023 as theREF_START_DATEand December 31, 2024 as theREF_END_DATE.
- When the
- Had to rename columns with same name to avoid conflicts with DuckDB. An example is table
10100164, it has two columns with the same name:ValueandVALUE. DuckDB treats column names in a case insensitive manner, so in these cases,Valuewas renamed toValue.1.
3. Issues Encountered
These are the issues I encountered when using Statistics Canada’s WDS.
3.1 Inconsistent Timezone Used for releaseTime
When using getAllCubesListLite, the releaseTime is in Coordinated Universal Time (UTC). However when you get the table metadata via getCubeMetadata, the releaseTime is in Eastern Standard Time (EST).
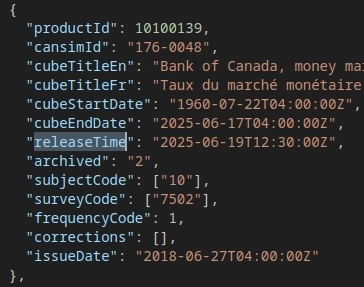
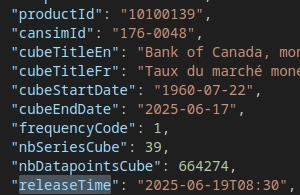
You can replicate this issue by running the following two commands. The first command gets the releaseTime for productId (table) 10100139 through getAllCubesListLite and the second command gets the releaseTime through getCubeMetadata.
# Get releaseTime for productId 10100139 via getAllCubesListLite
echo "This is the releaseTime for productId 10100139 retrieved through /getAllCubesListLite"
curl https://www150.statcan.gc.ca/t1/wds/rest/getAllCubesListLite | \
jq -r '.[] | select(.productId==10100139) | .releaseTime'# Get releaseTime for productId 10100139 via getCubeMetadata
echo "This is the releaseTime for productId 10100139 retrieved through /getCubeMetadata"
curl https://www150.statcan.gc.ca/t1/wds/rest/getCubeMetadata \
--header 'Content-Type: application/json' \
--data '[{"productId":10100139}]' | jq '.[0].object.releaseTime'3.2. Different releaseTime Values
There is a difference in some of the releaseTime values that are returned when using getAllCubesListLite or getCubeMetadata
For the example below there is a 3 year difference in the releaseTime.

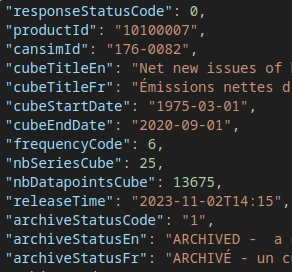
You can replicate this issue by running the following two commands. The first command gets the releaseTime for productId (table) 10100007 through getAllCubesListLite and the second command gets the releaseTime through getCubeMetadata.
# Get releaseTime for productId 10100007 via getAllCubesListLite
echo "This is the releaseTime for productId 10100007 retrieved through /getAllCubesListLite"
curl https://www150.statcan.gc.ca/t1/wds/rest/getAllCubesListLite | \
jq -r '.[] | select(.productId==10100007) | .releaseTime'# Get releaseTime for productId 10100007 via getCubeMetadata
echo "This is the releaseTime for productId 10100007 retrieved through /getCubeMetadata"
curl https://www150.statcan.gc.ca/t1/wds/rest/getCubeMetadata \
--header 'Content-Type: application/json' \
--data '[{"productId":10100007}]' | jq '.[0].object.releaseTime'3.3 Different Data Types for The productId
See the previous two examples. When using getAllCubesListLite, the productId is an integer. However when you get the table metadata via getCubeMetadata, the productId is a string. This is a minor issue.
3.4 Invalid DGUIDs
There are 6037 distinct invalid DGUIDs (see interactive list below). These records were found by finding any records that did not match the regular expression listed below. The regular expression was built from the definitions outlined in 1 and 2.
# Regular expression made from:
# https://www150.statcan.gc.ca/n1/pub/92f0138m/92f0138m2019001-eng.htm
# https://www12.statcan.gc.ca/census-recensement/2021/ref/dict/az/definition-eng.cfm?ID=geo055
pattern = r'^(?P<vintage>\d{4})(?P<type>[ASCBZ])(?P<schema>\d{4})(?P<guid>[A-Za-z0-9.]{1,11})$'I have noticed a few patterns:
- Some don’t have a
DGUID, but have aGEOvalue.- This makes sense in cases where the table is talking about geographies areas outside of Canada. For example, there are some
Mexicovalues. - There are multiple cases where there should be a
DGUID. Table43100008hasCanadaas theGEOvalue but has noDGUID. - Some cases would require a reworking of the
DGUID, for example table11100025has aGEOvalue ofAll census metropolitan areas, but it is doable.
- This makes sense in cases where the table is talking about geographies areas outside of Canada. For example, there are some
- Some are just regular geographic unique identifiers without the
Vintage,Type, andSchema. For exampleproduct_id13100409has aDGUIDof10, which is the Province and Territory code. - Some are completely wrong, such as table
38100162, which has aDGUIDof2016E200213.1.195.
3.5 Empty XML Data for Certain Tables
I processed all English CSV data, but I was curious how large of an XML we would get for the large CSV tables. I checked out table 98100404, which has a CSV file size of 37.67 GB, and when I tried to download it, it returned a 66.37 KB ZIP file, which is far too small. When I unzipped the file, it just returned the 98100404_Structure.xml, and it is missing the expected 98100404_1.xml file.
You can replicate the issue by running the following.
# Downloads the zipped up XML for productId 98100404
curl https://www150.statcan.gc.ca/t1/wds/rest/getFullTableDownloadSDMX/98100404 | \
jq -r '.object' | xargs curl -O3.6 Not Enough RAM!
I only have 32 GB of RAM on my PC, and as you can see on the table listed in 2. Result, the largest table is 120.09 GB. I had to get creative when processing it. I added a 400 GB swapfile and changed a couple of kernel parameters (see below) in /etc/sysctl.d.
# Goes up to 200. A higher value means the system will swap more aggressively. The default value is 60.
vm.swappiness = 200
# Controls the tendency of the kernel to reclaim the memory which is used for caching of directory and inode objects. The default value is 100.
vm.vfs_cache_pressure = 04. Next Steps
- Create a Dagster pipeline that automatically keeps the data up-to-date.
- Make sure that the data is accessible long-term by storing the data in Zenodo (operated by CERN). Zenodo allows versioning of a dataset, so we can keep track of the changes to each table.
- Create Python and R API bindings that use DuckDB. Users will be able to filter the data and also link the geographic boundaries if they wish. I am currently working on this in here.
5. Other
I made a brief 5 minute presentation on modernizing Statistics Canada data. You can view it here, best viewed in full screen.